py 决策树①
本文共 1968 字,大约阅读时间需要 6 分钟。
特点
它总是在沿着特征做切分。随着层层递进,这个划分会越来越细。虽然生成的树不容易给用户看,但是数据分析的时候,通过观察树的上层结构,能够对分类器的核心思路有一个直观的感受。举个简单的例子,当我们预测一个孩子的身高的时候,决策树的第一层可能是这个孩子的性别。男生走左边的树进行进一步预测,女生则走右边的树。这就说明性别对身高有很强的影响。
适用情景:因为它能够生成清晰的基于特征(feature)选择不同预测结果的树状结构,数据分析师希望更好的理解手上的数据的时候往往可以使用决策树。同时它也是相对容易被攻击的分类器。这里的攻击是指人为的改变一些特征,使得分类器判断错误。常见于垃圾邮件躲避检测中。因为决策树最终在底层判断是基于单个条件的,攻击者往往只需要改变很少的特征就可以逃过监测。受限于它的简单性,决策树更大的用处是作为一些更有用的算法的基石。
决策树算法
ID3是由Ross Quinlan在1985年建立的。这个方法建立多路决策树,并找到最大的信息增益。当树长到最大的尺寸,经常应用剪枝来提高决策树对未知数据的一般化。
C4.5是ID3的进一步延伸,通过将连续属性离散化,去除了特征的限制。C4.5将训练树转换为一系列if-then的语法规则。可确定这些规则的准确性,从而决定哪些应该被采用。如果去掉某项规则,准确性能提高,则应该实行修剪。
C5.0较C4.5使用更小的内存,建立更小的决策规则,更加准确。
CART和C4.5很相似,但是它支持数值的目标变量(回归)且不产生决策规则。CART使用特征和阈值在每个节点获得最大的信息增益来构建决策树。
scikit-learn使用一个最佳的CART算法
%matplotlib inlineimport matplotlib.pyplot as pltimport pandas as pdimport numpy as npfrom sklearn.datasets import make_blobsX, y = make_blobs(n_samples=300, centers=4, random_state=0, cluster_std=1.0)plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='rainbow');
from sklearn.tree import DecisionTreeClassifiertree = DecisionTreeClassifier().fit(X, y)def visualize_classifier(model, X, y, ax=None, cmap='rainbow'): ax = ax or plt.gca() # Plot the training points ax.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=cmap, clim=(y.min(), y.max()), zorder=3) ax.axis('tight') ax.axis('off') xlim = ax.get_xlim() ylim = ax.get_ylim() # fit the estimator model.fit(X, y) xx, yy = np.meshgrid(np.linspace(*xlim, num=200), np.linspace(*ylim, num=200)) Z = model.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape) # Create a color plot with the results n_classes = len(np.unique(y)) contours = ax.contourf(xx, yy, Z, alpha=0.3, levels=np.arange(n_classes + 1) - 0.5, cmap=cmap, clim=(y.min(), y.max()), zorder=1) ax.set(xlim=xlim, ylim=ylim) visualize_classifier(DecisionTreeClassifier(), X, y) 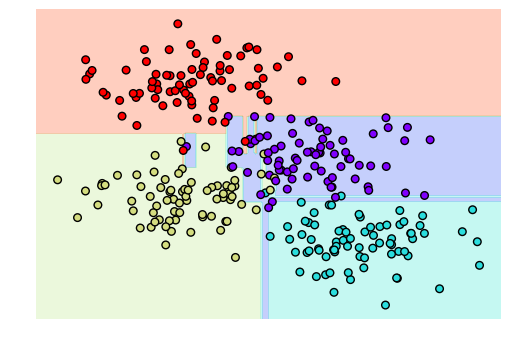
转载地址:http://kgtpl.baihongyu.com/
你可能感兴趣的文章
简单易用的库存管理软件、进销存软件
查看>>
docker WARNING: IPv4 forwarding is disabled. 解决方法
查看>>
Tomcat+Nginx+Memcached集群部署
查看>>
通过FFMPEG代码学习函数指针和指针函数
查看>>
H3 BPM MVC表单SheetOffice控件使用分享
查看>>
mysql innodb和myisam比较
查看>>
命令tree
查看>>
vue.js+vscode+visual studio在windows下搭建开发环境
查看>>
puppet 基础篇
查看>>
Java开发GUI之Dialog弹出窗口
查看>>
云架构的基础转变会带来哪些变化?
查看>>
如何将视频下载并且转码拼接
查看>>
Alcatraz插件安装问题
查看>>
轻松了解“Web应用防火墙”
查看>>
Kubernetes基础文档(链接,下载,安装,架构)
查看>>
PEEK材料再获突破,对3D打印产业影响几何
查看>>
无线加速度传感器
查看>>
设计模式
查看>>
Zend Studio 0x80070666错误解决
查看>>
Mac应用程序无法打开或文件损坏的处理方法
查看>>